Crackme 16: BinaryNewbie’s Tr1cky Cr4ckm3
Check out the page for this crackme on crackmes.one, or download the binary here.
First challenge: a password for $USER ¶
Running the program without arguments or a $USER environment variable makes it print an error message. If we set a value for $USER and try hello as the password, it runs without issues but reports that the password is incorrect:
$ export USER=binod
$ ./tricky-crackme hello
[+] Welcome to this tricky crackme.
[+] Find the correct password to unlock the next step.
[+] I'm waiting for solutions...
[+] Have fun.
[+] Developed by Binary Newbie
Wrong password :/
This is a pretty small executable at only 18,320 bytes but it seems to be written in C as it depends on libc.so.6 and contains symbols referencing C stdlib functions:
$ readelf -a ./tricky-crackme
[...]
000000201fa8 000c00000007 R_X86_64_JUMP_SLO 0000000000000000 strtol@GLIBC_2.2.5 + 0
000000201fb0 000d00000007 R_X86_64_JUMP_SLO 0000000000000000 gnu_get_libc_version@GLIBC_2.2.5 + 0
000000201fb8 000e00000007 R_X86_64_JUMP_SLO 0000000000000000 perror@GLIBC_2.2.5 + 0
000000201fc0 000f00000007 R_X86_64_JUMP_SLO 0000000000000000 exit@GLIBC_2.2.5 + 0
000000201fc8 001000000007 R_X86_64_JUMP_SLO 0000000000000000 fwrite@GLIBC_2.2.5 + 0
000000201fd0 001100000007 R_X86_64_JUMP_SLO 0000000000000000 __fprintf_chk@GLIBC_2.3.4 + 0
[...]
The ELF header says the entry point is at 0xd30 and Hopper names this section EntryPoint, but running the program in GDB with a breakpoint at 0xd30 just fails immediately without printing anything. Instead we can put a breakpoint on puts, which will eventually be called to print the welcome message. Then with a backtrace (bt) we’ll get the actual entry point for the program:
$ gdb ./tricky-crackme
[...]
gdb$ b puts
Breakpoint 1 at 0x950
gdb$ r
Starting program: ./tricky-crackme
Breakpoint 1, __GI__IO_puts (str=0x555555555288 "[+] Welcome to this tricky crackme.\n[+] Find the correct password to unlock the next step.\n[+] I'm waiting for solutions...\n[+] Have fun.\n[+] Developed by Binary Newbie\n") at ioputs.c:35
35 ioputs.c: No such file or directory.
=> 0x00007ffff7e79910 <__GI__IO_puts+0>: push r14
0x00007ffff7e79912 <__GI__IO_puts+2>: push r13
0x00007ffff7e79914 <__GI__IO_puts+4>: mov r13,rdi
0x00007ffff7e79917 <__GI__IO_puts+7>: push r12
0x00007ffff7e79919 <__GI__IO_puts+9>: push rbp
0x00007ffff7e7991a <__GI__IO_puts+10> push rbx
0x00007ffff7e7991b <__GI__IO_puts+11> call 0x7ffff7e2a130 <*ABS*+0x88070@plt>
0x00007ffff7e79920 <__GI__IO_puts+16> mov r12,QWORD PTR [rip+0x149621] # 0x7ffff7fc2f48
0x00007ffff7e79927 <__GI__IO_puts+23> mov rbx,rax
gdb$ bt
#0 __GI__IO_puts (str=0x555555555288 "[+] Welcome to this tricky crackme.\n[+] Find the correct password to unlock the next step.\n[+] I'm waiting for solutions...\n[+] Have fun.\n[+] Developed by Binary Newbie\n") at ioputs.c:35
#1 0x0000555555554aad in ?? ()
#2 0x00007ffff7e2c09b in __libc_start_main (main=0x555555554a80, argc=0x1, argv=0x7fffffffed48, init=<optimized out>, fini=<optimized out>, rtld_fini=<optimized out>, stack_end=0x7fffffffed38) at ../csu/libc-start.c:308
#3 0x0000555555554d5a in ?? ()
In this stack trace we see __libc_start_main which is the libc function that run before main itself and then the breakpoint on __GI__IO_puts. The main parameter tells us that the program starts at 0x555555554a80, with the following instructions:
$ x/20i 0x555555554a80
0x555555554a80: push rbp
0x555555554a81: push rbx
0x555555554a82: mov ebx,edi
0x555555554a84: lea rdi,[rip+0x7fd] # 0x555555555288
0x555555554a8b: mov rbp,rsi
0x555555554a8e: sub rsp,0xb8
0x555555554a95: mov rax,QWORD PTR fs:0x28
0x555555554a9e: mov QWORD PTR [rsp+0xa8],rax
0x555555554aa6: xor eax,eax
0x555555554aa8: call 0x555555554950 <puts@plt> ; the call to puts()
0x555555554aad: cmp ebx,0x2
0x555555554ab0: je 0x555555554af6
...
In Hopper we can navigate to address 0xa80 and use Modify > Change File Base Address from 0x00 to 0x555555554000, which will make it match GDB.
Note the cmp ebx, 0x2 followed by a je: ebx is set above to what was in edi. This register is set by __libc_start_main and stores the number of arguments passed to the program. If it’s 2 then a single password parameter was passed in and we jump, otherwise we continue and there are instructions that mention stderr and Usage %s <password>\n.
The code that follows is executed when we do have a parameter. It looks very unusual:
$ x/26i 0x555555554af6
0x555555554af6: movdqa xmm0,XMMWORD PTR [rip+0x852] # 0x555555555350
0x555555554afe: lea rbx,[rsp+0x1e]
0x555555554b03: mov rdi,QWORD PTR [rbp+0x8]
0x555555554b07: mov edx,0xa
0x555555554b0c: xor esi,esi
0x555555554b0e: movaps XMMWORD PTR [rsp+0x60],xmm0
0x555555554b13: mov DWORD PTR [rsp+0x1e],0x4d5a4c4a
0x555555554b1b: mov BYTE PTR [rsp+0x22],0x1f
0x555555554b20: movdqa xmm0,XMMWORD PTR [rip+0x838] # 0x555555555360
0x555555554b28: mov BYTE PTR [rsp+0xa0],0x1b
0x555555554b30: mov BYTE PTR [rsp+0xa1],0x5f
0x555555554b38: movaps XMMWORD PTR [rsp+0x70],xmm0
0x555555554b3d: mov BYTE PTR [rsp+0xa2],0x45
0x555555554b45: mov BYTE PTR [rsp+0xa3],0x57
0x555555554b4d: movdqa xmm0,XMMWORD PTR [rip+0x81b] # 0x555555555370
0x555555554b55: mov BYTE PTR [rsp+0xa4],0x75
0x555555554b5d: mov BYTE PTR [rsp+0xa5],0x7f
0x555555554b65: movaps XMMWORD PTR [rsp+0x80],xmm0
0x555555554b6d: mov BYTE PTR [rsp+0x50],0xe3
0x555555554b72: mov BYTE PTR [rsp+0x51],0xc6
0x555555554b77: movdqa xmm0,XMMWORD PTR [rip+0x801] # 0x555555555380
0x555555554b7f: mov BYTE PTR [rsp+0x52],0xcc
0x555555554b84: movaps XMMWORD PTR [rsp+0x90],xmm0
0x555555554b8c: movdqa xmm0,XMMWORD PTR [rip+0x7fc] # 0x555555555390
0x555555554b94: movaps XMMWORD PTR [rsp+0x40],xmm0
0x555555554b99: call 0x5555555549c0 <strtol@plt>
Many of these are double-quadword instructions, moving 128 bits at a time. MOVDQA is “Move Aligned Double Quadword”, and MOVAPS is “Move Aligned Packed Single-Precision (floating-point values)”.
But let’s start with first two mov followed by a xor. These set rdi, edx, and esi.
The first mov sets rdi to the value at rbp + 0x08: rbp is the frame pointer, so at +8 this is our first argument to main. Indeed we can verify this with a breakpoint at 0x555555554b03:
gdb$ b *0x555555554b03
Breakpoint 1 at 0x555555554b03
gdb$ r hello
Starting program: ./tricky-crackme hello
[+] Welcome to this tricky crackme.
[...]
Breakpoint 1, 0x0000555555554b03 in ?? ()
=> 0x0000555555554b03: 48 8b 7d 08 mov rdi,QWORD PTR [rbp+0x8]
gdb$ printf "%s", *(char**)($rbp+8)
hello
Then edx is set to 10, and esi is zero’d. These are the 3 parameters for the call to strtol at 0x555555554b99, meaning our input password is being read as a number in base 10, not a string. This is important and dramatically reduces the potential number of values that would be accepted. It also tells us that the input string "hello" is not going to work here.
If we continue after the call to strtol:
0000555555554b9e mov esi, 0x5 ; argument #2 for method sub_e40
0000555555554ba3 mov rdi, rbx ; argument #1 for method sub_e40
0000555555554ba6 mov rbp, rax
0000555555554ba9 call sub_e40 ; sub_e40
0000555555554bae mov rdi, rbx ; argument "__name" for method j_secure_getenv
0000555555554bb1 call j_secure_getenv ; secure_getenv
0000555555554bb6 test rax, rax
0000555555554bb9 je loc_555555554caf
Recall that we had a lea rbx,[rsp+0x1e] above, so the value of rbx is just rsp + 0x1e; we’re putting this in the first parameter rdi, then 5 in the second parameter esi, and we call this mysterious sub_40 function that we haven’t seen yet.
The flow chart for this sub_40 shows a sequence of simple code blocks doing a single xor between a value in r9 and successive bytes pointed by rdi:
Zooming in, we can see the sequence of blocks for increasing values of `i`:
movzx eax, byte [r9]
xor byte [rdi+`i`], al
cmp edx, `i+1`
je right_branch
where right_branch is
mov eax, `i+1`
jmp further_down
Highlighted in pairs:
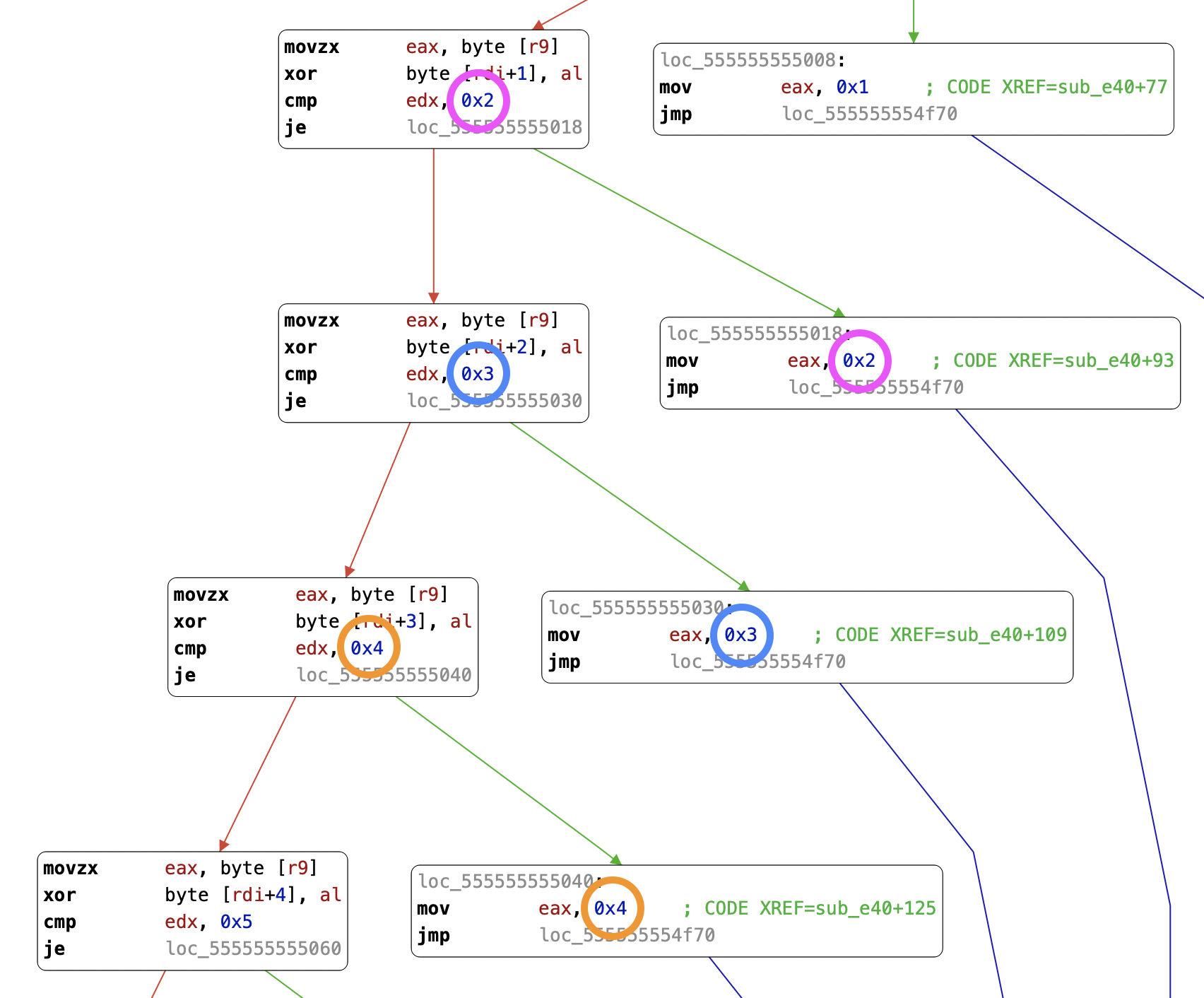
Which is an unrolled version of:
for (i = 0; i != edx; i++) {
rdi[i] = rdi[i] ^ r9;
}
Note: we’ll see in the rest of the article that loops that go over a buffer XOR-ing each byte with a hardcoded byte value is a common pattern used in this program to obfuscate strings.
With this in mind, let’s look at rbx at the start of this function call. It points to an address containing a few bytes:
$ x/5b $rbx
0x7fffffffebae: 0x4a 0x4c 0x5a 0x4d 0x1f
At the top of sub_e40 we start with esi set to 5 (it’s the second parameter in the function call), and compare it with 0x12 which is the maximum length of strings the function can decode. We also make r9 point the esi - 1th byte in the string (in our case, 0x1f), with these two instructions where rdx is also the length and rdi also points to the same string as rbx:
0000555555554e4e lea rax, qword [rdx-1] ; rdx is also the length, 5
0000555555554e52 lea r9, qword [rdi+rax] ; rdi also points to the string to decode, so r9=str[4]
We jump to a simple loop that XORs each value of rdi with the byte at r9:
0000555555554ff0 movzx eax, byte [r9] ; <―――╮
0000555555554ff4 xor byte [rdi], al ; │
0000555555554ff6 add rdi, 0x1 ; │
0000555555554ffa cmp rdi, rdx ; │
0000555555554ffd jne 555555554ff0 ; ――――╯ loop back up
0000555555554fff ret
These bytes are updated in place but rdi keeps incrementing. Recall that we had saved a pointed to the start of the buffer in rdx, and indeed when we ret from sub_e40 this value is used as the first parameter to secure_getenv. Let’s just compute this value:
rbx starts with 4A 4C 5A 4D 1F and each byte is XOR’d in place with the byte at r9 which is 0x1f:
>>> ''.join(map(lambda c: chr(c ^ 0x1F), [0x4A, 0x4C, 0x5A, 0x4D]))
'USER'
So this is where our USER environment variable is coming from, despite not appearing in clear in the output of strings.
With the environment variable in rax (the return value of secure_getenv), we place it in rdi (the register often used for the first parameter of a function call) and call sub_10f0. The function starts with a short loop to compute the size of the input string:
0000555555555104 mov rax, rdi ; rax points to first byte of input
0000555555555107 nop word [rax+rax] ; not sure what this is about
loc_555555555110:
0000555555555110 add rax, 0x1 ; increment counter rax
0000555555555114 cmp byte [rax-1], 0x0 ; reached null byte at end of string?
0000555555555118 jne loc_555555555110 ; if not, loop
000055555555511a sub rax, rdi ; then compute rax = (rax - start of string)
0000555555555125 lea rdx, qword [rax-1] ; and store rax-1 into rdx.
We end up with the string length in rdx, not including the terminating null byte.
This is followed by ecx and eax being cleared, and then a loop that goes over the input and XORs all the bytes together and each with its offset and 0x0f:
loc_555555555168:
0000555555555168 movsx rsi, byte [rdi+rcx] ; rsi takes the i_th byte at offset rcx <―――╮
000055555555516d add rax, rsi ; we add it to rax (which started at zero) │
0000555555555170 xor rax, rcx ; we XOR this value with the current offset rcx │
0000555555555173 add rcx, 0x1 ; increment rcx │
0000555555555177 xor rax, 0xf ; XOR the value again with 0xf this time │
000055555555517b cmp rdx, rcx ; have we reached the end of the string? │
000055555555517e jne loc_555555555168 ; if not, jump back to top of the loop ―――╯
Translated to pseudo-C:
int rax = 0, rcx = 0, rdx = length;
do {
rax = rax + input[rcx];
rax = rax ^ rcx;
rcx++;
rax = rax ^ 0xf;
} while (rcx != rdx)
Applied to the user name taken from $USER, this gives us the first password.
In Python:
>>> user = 'binod'
>>> reduce(lambda acc, cur: (acc + ord(cur[0])) ^ cur[1] ^ 0xf, zip(user, range(len(user))), 0)
529
Let’s try it:
$ USER=binod ./tricky-crackme 123
[+] Welcome to this tricky crackme.
[...]
Wrong password :/
$ USER=binod ./tricky-crackme 529
[+] Welcome to this tricky crackme.
[...]
Enter the password:
But as the welcome message says, “Find the correct password to unlock the next step”, so let’s continue with the second password.
Enter the password: hunter2
Invalid charset
After the password for $USER is validated, we jump to 0x555555554bf7 and land on some tricky moves of large constants before calling again the sub_e40 function which XORs its string input in place with its last byte. We can tell the length is 13 this time, from the mov esi, 0xd:
0000555555554bf7 lea rbx, qword [rsp+0x23] ; rbx points to rsp+0x23
0000555555554bfc movabs rax, 0xb8e6afa5a4a8aeb8 ; copies 8 bytes into rax
0000555555554c06 mov esi, 0xd ; argument #2 for method sub_e40
0000555555554c0b mov qword [rsp+0x23], rax
0000555555554c10 mov dword [rsp+0x2b], 0xaeacaabf ; copies 4 bytes
0000555555554c18 mov rdi, rbx ; argument #1 for method sub_e40
0000555555554c1b mov byte [rsp+0x2f], 0xcb ; copies 1 byte
0000555555554c20 call sub_e40
We can put breakpoints on the call instruction and just after it to see its input and what it produces:
gdb$ b *0x0000555555554c20
Breakpoint 1 at 0x555555554c20
gdb$ b *0x0000555555554c25
Breakpoint 2 at 0x555555554c25
gdb$ r 529
[...]
Breakpoint 1, 0x0000555555554c20 in ?? ()
=> 0x0000555555554c20: e8 1b 02 00 00 call 0x555555554e40
gdb$ x/14b $rdi
0x7fffffffebb3: 0xb8 0xae 0xa8 0xa4 0xa5 0xaf 0xe6 0xb8
0x7fffffffebbb: 0xbf 0xaa 0xac 0xae 0xcb 0x0
gdb$ c
Continuing.
Note that we could have reconstructed this from the code alone: we have rbx pointing to rsp + 0x23, then the two copies.
First, the 8 bytes at rsp + 0x23, then the 4 bytes at rsp + 0x2b, and then the last byte at rsp + 0x2f:
| First copy (8 bytes) | Second copy (4 bytes) | Third copy (1 byte) | |
|---|---|---|---|
| Destination | rsp + 0x23 | rsp + 0x2b | rsp + 0x2f |
| Bytes | b8 ae a8 a4 a5 af e6 b8 | bf aa ac ae | cb |
| Instruction address | 0x555555554bfc | 0x555555554c10 | 0x555555554c1b |
If we dump $rbx after returning from the call, we get the decoded string second-stage:
Breakpoint 2, 0x0000555555554c25 in ?? ()
=> 0x0000555555554c25: 48 89 de mov rsi,rbx
gdb$ x/14b $rbx
0x7fffffffebb3: 0x73 0x65 0x63 0x6f 0x6e 0x64 0x2d 0x73
0x7fffffffebbb: 0x74 0x61 0x67 0x65 0x0 0x0
gdb$ printf "%s", $rbx
second-stage
Let’s double-check using the same XOR-based decryption function as earlier, the last byte being 0xcb this time:
>>> ''.join(map(lambda c: chr(c ^ 0xCB), [0XB8,0XAE,0XA8,0XA4,0XA5,0XAF,0XE6,0XB8,0XBF,0XAA,0XAC,0XAE]))
'second-stage'
Seeing a recognizable value after a decoding function tells us that we’re on the right track.
A few instructions then prepare the arguments for a system call (rbx points to the string "second-stage" and 0x13f is 319):
0000555555554c25 mov rsi, rbx
0000555555554c28 xor eax, eax
0000555555554c2a mov edx, 0x1
0000555555554c2f mov edi, 0x13f ; argument "__sysno" for method j_syscall
0000555555554c34 mov qword [rsp+0xc8+var_C8], rbx
0000555555554c38 mov qword [rsp+0xc8+var_C0], 0x0
0000555555554c41 call j_syscall
Here the syscall number is not in rax but in edi, and 0x13 is identified by Hopper as the __sysno parameter, or system call number. This system call is memfd_create (man page), which “creates an anonymous file and returns a file descriptor that refers to it”.
After this file is created, a call to write copies 0x2008 or 8,200 bytes into it and jumps if all went well. Here Hopper recognizes that the buffer being copied starts with 0x7F and ELF, which are the first 4 bytes in an ELF binary. It seems highly likely that we just created a new binary that we’ll end up executing.
0000555555554c52 lea rsi, qword [aElf] ; argument "__buf" for method j_write, "?ELF"
0000555555554c59 mov edx, 0x2008 ; argument "__n" for method j_write
0000555555554c5e mov edi, eax ; argument "__fd" for method j_write
0000555555554c60 call j_write ; write
0000555555554c65 cmp rax, 0x2008
0000555555554c6b je loc_555555554cbe
And indeed this is followed by a call to fexecve:
0000555555554cbe mov rdx, qword [__environ] ; argument "__envp" for method j_fexecve, __environ
0000555555554cc5 mov rsi, rsp ; argument "__argv" for method j_fexecve
0000555555554cc8 mov edi, ebx ; argument "__fd" for method j_fexecve
0000555555554cca call j_fexecve ; fexecve
Let’s extract these 8,200 bytes into a file to start analyzing it.
The second (hidden) binary ¶
Running the extracted binary, we can already observe the same behavior as in the parent program:
$ ./extracted-8200.bin
Enter the password: hunter2
Invalid charset
readelf reveals a broken ELF header:
# readelf -a ./extracted-8200.bin
ELF Header:
Magic: 7f 45 4c 46 00 00 00 00 00 00 00 00 00 00 00 00
Class: none
Data: none
Version: 0
OS/ABI: UNIX - System V
ABI Version: 0
Type: DYN (Shared object file)
Machine: Advanced Micro Devices X86-64
Version: 0x0
Entry point address: 0xbd0
Start of program headers: 0 (bytes into file)
Start of section headers: 64 (bytes into file)
Flags: 0x0
Size of this header: 0 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 0 (bytes)
Number of section headers: 0
Section header string table index: 0
readelf: Warning: possibly corrupt ELF file header - it has a non-zero section header offset, but no section headers
There are no sections to group in this file.
There are no program headers in this file.
There is no dynamic section in this file.
As a result, GDB doesn’t recognize the binary and can’t run it:
$ gdb ./extracted-8200.bin
[...]
"./extracted-8200.bin": not in executable format: file format not recognized
By going over the ELF header, we can find a few missing fields to add back:
| Offset | Field | Original value | New value | New meaning |
|---|---|---|---|---|
| 4 | e_ident[EI_CLASS] | 00 | 02 | 64-bit format |
| 5 | e_ident[EI_DATA] | 00 | 01 | little endian |
| 6 | e_ident[EI_VERSION] | 00 | 01 | Constant (1 for ELF) |
| 20 | e_version | 00 00 00 00 | 01 00 00 00 | Constant (1 for ELF) |
These few changes are simple enough that they can be made with a hex editor, but we could also use the Lepton library:
#!/usr/bin/python3
from lepton import *
from struct import pack
with open("extracted-8200.bin", "rb") as fin:
elf_file = ELFFile(fin)
ident = bytearray(elf_file.ELF_header.fields['e_ident']) # update header
ident[4] = 2
ident[5] = 1
ident[6] = 1
elf_file.ELF_header.fields['e_ident'] = bytes(ident)
elf_file.ELF_header.fields['e_version'] = pack("<L", 1)
binary = elf_file.ELF_header.to_bytes() + elf_file.file_buffer[64:] # write back
with open("extracted-8200-fixed.bin", "wb") as fout:
fout.write(binary)
With these few changes saved to a new binary, readelf is a bit more helpful and we get at least the entry point which is at 0xbd0. If we disassemble this section in Hopper, we see a few lea instructions before a call and hlt:
0000000000000bdf lea r8, qword [EntryPoint+2048] ; 0x13d0
0000000000000be6 lea rcx, qword [EntryPoint+1936] ; 0x1360
0000000000000bed lea rdi, qword [0xa50] ; 0xa50
0000000000000bf4 call qword [0x201fe0] ; 0x201fe0
0000000000000bfa hlt
We don’t have symbols at this point, but if this is similar to the first binary this could be a call to __libc_start_main, which would mean that 0xa50 is our main function. There, we see a couple of call instructions to functions that immediately jump somewhere else (could be external functions), followed by the now-familiar instructions manipulating large values that likely encode messages:
0000000000000a83 movabs rax, 0xc2de8ad8cfdec4ef
0000000000000a8d mov qword [rsp+0x20], rax
0000000000000a92 movabs rax, 0xc5ddd9d9cbda8acf
0000000000000a9c mov dword [rsp+0x30], 0x8a90ced8
0000000000000aa4 mov qword [rsp+0x28], rax
0000000000000aa9 mov byte [rsp+0x34], 0xaa
| 1st copy (8 bytes) | 2nd copy (4 bytes) | 3rd copy (8 bytes) | 4th copy (1 byte) | |
|---|---|---|---|---|
| Offset | rsp + 0x20 | rsp + 0x30 | rsp + 0x28 | rsp + 0x34 |
| Bytes | c2 de 8a d8 cf de c4 ef | 8a 90 ce d8 | c5 dd d9 d9 cb da 8a cf | aa |
Once again we encounter code that XORs a sequence of bytes with the one it ends with:
0000000000000ad0 movzx ecx, byte [rsp+0x34] ; we've just put 0xaa there <―――╮
0000000000000ad5 xor byte [rax], cl ; XOR the current character │
0000000000000ad7 add rax, 0x1 ; increment the pointer │
0000000000000adb cmp rsi, rax ; have we reached the end? │
0000000000000ade jne 0xad0 ; if not, loop back up. ――――╯
Let’s decode it:
>>> bytes = []
>>> bytes += 'c2 de 8a d8 cf de c4 ef'.split(' ')[::-1]
>>> bytes += 'c5 dd d9 d9 cb da 8a cf'.split(' ')[::-1]
>>> bytes += '8a 90 ce d8'.split(' ')[::-1]
>>> bytes += ['aa']
>>> ''.join(map(lambda h: chr(int(h, 16) ^ 0xaa), bytes))
'Enter the password: \x00'
We can safely assume this is followed by a call instruction to write out this string, likely with these instructions:
0000000000000ae0 lea rsi, qword [EntryPoint+2068]
0000000000000ae7 mov edi, 0x1 ; presumably this is fd=1 (stdout)
0000000000000aec xor eax, eax
0000000000000aee lea rbx, qword [rsp+0x40]
0000000000000af3 call 0x9c0
This call instruction is followed almost immediately by a second call. One thing to notice here is the lack of a new line at the end of the decode string, and how the program presents a prompt for the password on the same line as the “Enter…” string. To achieve this, this second call would likely have to be for fflush(). Once this is printed, we can assume that a read of fgets will follow to receive the password:
0000000000000b13 call 0x970 ; gets/fgets?
0000000000000b18 test rax, rax ; check if empty
0000000000000b1b mov rdx, rbx
0000000000000b1e je 0xb96 ; jump somewhere else if input was empty
0000000000000b20 add rdx, 0x1
0000000000000b24 cmp byte [rdx-1], 0x0
0000000000000b28 jne 0xb20
0000000000000b2a sub rdx, rbx
0000000000000b2d mov rdi, rbx
0000000000000b30 mov byte [rsp+rdx+0x3e], 0x0
0000000000000b35 call EntryPoint+960 ; call to some unknown function
0000000000000b3a test al, al
0000000000000b3c jne 0xb8a
0000000000000b3e mov rsi, qword [qword_202040]
0000000000000b45 movabs rax, 0x2064696c61766e49 ; this is the string "Invalid "
0000000000000b4f mov rdi, rsp
0000000000000b52 mov qword [rsp], rax
0000000000000b56 movabs rax, 0xa74657372616863 ; the string "charset\n"
We did observe the “Invalid charset” error message with our "hunter2" input earlier, and we can see here that this is due to a non-zero return value from the call made at 0x0b35.
At this point it would be very useful to have a way to debug this program and trace its steps with GDB. Unfortunately a ptrace(PTRACE_TRACEME) call prevents this: it returns -1 when GDB is already tracing the execution. Hopper can’t find symbols for this binary but Binary Ninja does, identifying the call to ptrace at offset 0x0a2e:
0000000000000a2e call 0x9b0 ; calls ptrace()
0000000000000a33 cmp rax, 0xffffffffffffffff ; compares return value to -1
0000000000000a37 je 0xa3e ; jumps to exit if it matches
0000000000000a39 add rsp, 0x8
0000000000000a3d ret ; returns from the call
0000000000000a3e mov edi, 0x1 ; exit code 1
0000000000000a43 call 0x9e ; calls exit()
As in a previous challenge, we can just NOP the CMP and JE instructions and just disregard the return value from ptrace. We change these 6 bytes into 0x90 and produce a new binary that we can try in GDB. Here is the same section after the change:
0000000000000a2e call 0x9b0 ; calls ptrace()
0000000000000a33 nop ; the CMP call above took 6 bytes,
0000000000000a34 nop ; added here as 6 individual one-byte NOPs
0000000000000a35 nop ; ...
0000000000000a36 nop ; ...
0000000000000a37 nop ; ...
0000000000000a38 nop ; ...
0000000000000a39 add rsp, 0x ; and we continue as if nothing had happened.
After this second change to the extracted binary, we can finally start this new program in GDB and break on one of the magic values used to print strings:
gdb$ starti
Starting program: ./extracted-8200-fixed-no-ptrace.bin
...
Program stopped.
0x00007ffff7fd6090 in ?? ()
=> 0x00007ffff7fd6090: 48 89 e7 mov rdi,rsp
gdb$ watch $rax == 0xc2de8ad8cfdec4ef
Watchpoint 1: $rax == 0xc2de8ad8cfdec4ef
gdb$ c
Continuing.
Watchpoint 1: $rax == 0xc2de8ad8cfdec4ef
Old value = 0x0
New value = 0x1
0x0000555555554a8d in ?? ()
=> 0x0000555555554a8d: 48 89 44 24 20 mov QWORD PTR [rsp+0x20],rax
This gives us our file offset 0x0000555555554000 which we can change in Hopper as earlier. With GDB and Hopper addresses now matching, this makes comparing the two much easier.
Two other symbols found by Binary Ninja are time and srand, called here:
0000555555554a65 xor eax, eax ; presumably the parameter to time()
0000555555554a67 call 0x555555554980 ; time
0000555555554a6c mov edi, eax ; moves the return value of time() into the parameter for srand()
0000555555554a6e call 0x555555554960 ; srand
Calling srand(time(NULL)) is a classic way to initialize a PRNG before generating random numbers; let’s hope that the program is deterministic and that the password is not time-dependent.
After reading the input with fgets, we compute the input length and then jump to 0x0000555555554f90. From there we call __ctype_b_loc, a function which returns a table describing traits associated with each character. We are presumably going to use it to validate the input string.
Indeed this is followed by a loop (starting at 0x0000555555554fd1) which goes over the input and looks up each character in the array returned by __ctype_b_loc:
; ╭───── (jump from above to 0000555555554fd1)
0000555555554fc8 add rax, 0x1 ;<───┼──╮
0000555555554fcc cmp rax, rbx ; │ │ have we reached the end?
0000555555554fcf je EntryPoint+103 ; │ │ if so, jump to the cmp below.
0000555555554fd1 movsx rdx, byte [rbp+rax] ;<───╯ │ entry point: rdx is our current character
0000555555554fd7 test byte [rcx+rdx*2+1], 0x8 ; │ compare array[chr*2+1] with the value 8
0000555555554fdc jne EntryPoint+1016 ;―――――――╯ if they don't match, go to the top
0000555555554fde cmp rbx, rax ; check if we're at the end of the string
0000555555554fe1 sete al ; if so, set al to 1, otherwise 0.
0000555555554fe4 add rsp, 0x8
0000555555554fe8 pop rbx
0000555555554fe9 pop rbp
0000555555554fea ret
Which is something like:
rbx = length;
rcx = __ctype_b_loc(input, rbx); // returns an array describing each character, in rcx
for (rax = 0; rax < rbx; rax++) {
rdx = input[rax]; // take current character
if (rcx[rdx * 2 + 1] != 8) { // check in ctype array (note the access using odd offsets)
continue;
}
}
if (rax == rbx) {
al = 1; // return success
}
In ctype.h, the definition of _ISdigit reveals the purpose of this loop:
_ISdigit = ((3) < 8 ? ((1 << (3)) << 8) : ((1 << (3)) >> 8))
_ISdigit is (1 << 3) << 8, or 2048. In hex this is 0x0800 so since each entry is 2 bytes we first need to multiply the index by 2 and then add 1 to get the upper byte, giving us rdx * 2 + 1. This loop is simply checking that the input is composed only of valid digits. Note that isdigit(3) (man page) also relies on the character traits table returned by __ctype_b_loc.
After this call we return to an expected test al, al and if al not zero we jump to 0x0x555555554b8a and call 0x0000555555555130.
We start with yet another manual strlen:
0000555555555134 mov r12, rdi ; save our input in r12
...
000055555555514d mov rax, rdi ; rdi is out input, move it to rax
0000555555555150 add rax, 0x1 ; increment pointer
0000555555555154 cmp byte [rax-1], 0x0 ; check whether we're 1 byte past the end of the string
0000555555555158 jne 0x0000555555555150 ; if not, go back 2 lines up
000055555555515a sub rax, r12 ; subtract from saved pointer
000055555555515d mov rbx, rax ; at this point rax and rbx are length + 1
0000555555555160 lea rdi, qword [rax-1] ; save rax-1 or length to rdi
0000555555555164 lea rax, qword [rax-3] ; save rax-3 or length-2 to rax
After this loop rax is now input length - 2, e.g. 4 for the password “12345”, and rdi is the exact input length.
We follow with two comparisons to 0xe (14) and 1, before calling malloc if the length falls in the expected range:
0000555555555168 cmp rax, 0xe ; if rax > 14
000055555555516c ja call_puts+522 ; jump somewhere
0000555555555172 test dil, 0x1 ; if dil & 1 != 0
0000555555555176 jne call_puts+465 ; jump somewhere else
000055555555517c shr rdi, 0x1 ; shift rdi right by 1
000055555555517f mov r13d, edi ; save it to r13d
0000555555555182 shl rdi, 0x2 ; shift left by 2
0000555555555186 call 0x555555554990 ; (call malloc)
Or approximately:
rax = len - 2;
if (rax <= 14 && (len % 2 == 0)) {
rdi = len >> 1; // that's len / 2
r13d = edi;
rdi <<= 2; // and we multiply by 4 this time
malloc(rdi); // so the allocated buffer size is 2x the length
}
This gives us a maximum input length, and we continue with more comparisons:
000055555555518b test rax, rax ; check rax (the return value from malloc)
000055555555518e mov rbp, rax ; save rax to rbp
0000555555555191 je call_puts+470 ; if rax is zero, jump off somewhere
0000555555555197 sub rbx, 0x2 ; rbx -= 2 (we had rbx equal to length + 1 until now)
000055555555519b xor eax, eax ; reset eax to zero
000055555555519d shr rbx, 0x1 ; rbx >>= 1 (so rbx is now 2 * (length - 1))
00005555555551a0 lea rsi, qword [rbx+1] ; rsi = rbx+1
00005555555551a4 nop dword [rax] ; multi-byte NOP
00005555555551a8 cmp r13d, eax ; if r13d <= eax
00005555555551ab jle call_puts+349 ; then jump out
00005555555551ad movsx cx, byte [r12+rax*2] ; move and sign-extend the byte at r12 + rax * 2 into cx (r12 points to our input)
00005555555551b3 sub ecx, 0x30 ; ecx -= 0x30 (0x30 is the ascii code for '0')
00005555555551b6 cmp cx, 0x2 ; if cx > 2
00005555555551ba ja call_puts+457 ; then jump below to a free call
00005555555551c0 movsx dx, byte [r12+rax*2+1] ; select the next byte, copy into dx this time
00005555555551c7 sub edx, 0x30 ; again take the difference with '0'
00005555555551ca cmp dx, 0x3 ; compare to 3
00005555555551ce ja call_puts+457 ; jump if it's strictly greater, also to free
00005555555551d0 mov word [rbp+rax*4], cx ; copy this first character into our malloc'd buffer
00005555555551d5 mov word [rbp+rax*4+2], dx ; then the second
00005555555551da add rax, 0x1 ; increment rax, which we now see is an offset
00005555555551de cmp rax, rsi ; compare to rsi
00005555555551e1 jne 0x00005555555551a8 ; if we're not there yet, loop back up to cmp r13d, eax
Simplified:
eax = 0;
while (eax < length/2) {
cx = input[eax * 2]; // read one byte as cx
if (cx <= 2) {
dx = input[eax * 2 + 1]; // read the next as dx
if (dx <= 3) {
output[rax * 4] = (short) cx; // copies cx into output at offset rax * 4
output[rax * 4 + 2] = (short) dx; // and dx at offset rax * 4 + 2
rax++;
}
}
}
// ...
call_free:
free(output);
So we go from zero to length/2 reading two bytes at a time, the first needs to be between '0' and '2' and the second between '0' and '3', copying them into a buffer at 4 * i and 4 * i + 2 with i++ at each turn.
Once we’re done with this initial loop writing to the allocated buffer, a second one goes over the data we just wrote:
0000555555555200 movsx rcx, word [rbp+rax*4] ; read the cx byte
0000555555555206 movsx rdx, word [rbp+rax*4+2] ; read the dx byte
000055555555520c lea rcx, qword [rsi+rcx*4] ; set rcx to rsi (the constant "G0B04JD\x00NP " + 4*cx)
0000555555555210 movzx edx, byte [rcx+rdx] ; and add dx
0000555555555214 test dl, dl ; check whether it's zero
0000555555555216 mov byte [rdi+rax], dl ; copy into rdi using offset rax
0000555555555219 je call_puts+414 ; jump out
000055555555521b add rax, 0x1 ; increment offset
000055555555521f cmp r13d, eax ; compare to length/2
0000555555555222 jg call_puts+378 ; loop back to start
Here rsi points to a set of bytes that start with G0B04JD\x00NP (the last byte is a space).
With rax used as a cursor, at each iteration we take the two bytes cx and dx computed above (which are just the input digits taken in pairs) and copy the one in rsi at offset (cx * 4 + dx) into rdi at offset rax. We break only if the byte is zero or if we’ve reached the end of the input string:
rax = 0;
rsi = "G0B04JD\x00NP ";
while (rax < length/2) {
cx = output[rax * 4]; // same two bytes as
dx = output[rax * 4 + 2]; // in the previous loop
offset = cx * 4 + dx; // compute offset into constant string
dl = rsi[offset]; // copy byte
rdi[rax] = dl; // into buffer for puts()
if (!dl) break;
}
At the end of this loop, the buffer at rdi that was populated with these individual bytes copies is sent to puts, then the buffer is free’d and the program exits. No error message is reachable from this point, so based on this logic we can predict what string will be constructed depending on the digit pairs that are typed in.
If we enter just 12 then cx is 1 and dx is 2, so cx * 4 + dx is 6 and only the character D will be produced:
Enter the password: 12
D
We can therefore create the following table:
| Pair of digits | Offset into rsi | Character produced |
|---|---|---|
| 00 | 0 | G |
| 01 | 1 | 0 |
| 02 | 2 | B |
| 03 | 3 | 0 |
| 10 | 4 | 4 |
| 11 | 5 | J |
| 12 | 6 | D |
| 13 | 7 | \x00 |
| 20 | 8 | N |
| 21 | 9 | P |
| 22 | 10 | (space) |
| 23 | 11 | \x00 |
Note that multiple digit pairs produce the same output character, so all the 01 input pairs could also use 03.
If we want to print G00D J0B, we can type in 0001011222110102 (or 0003031222110302):
Enter the password: 0001011222110102
G00D J0B
...
Enter the password: 0003031222110302
G00D J0B
There is no code past this point that attempts to validate the password, so we can assume the challenge ends here since we control the output:
Enter the password: 0001011222201021
G00D N4P
...
Enter the password: 0210122220010102
B4D N00B
Closing thoughts ¶
The crackme was ranked as a level 4 (“hard”) on crackmes.one, and it was probably the most challenging one featured here so far. There were multiple layers of obfuscation and counter-measures, from ELF header changes to using __libc_start_main to extracting a new binary before calling fexecve and even preventing ptrace from being called.
Breaking the ELF header made the reverse-engineering process much harder, mostly because it took me a long time to find the real entry point address in the second binary.